

Description
MongoDB의 "Know-How"가 아닌 "Know-Why"를 전달해 드립니다!
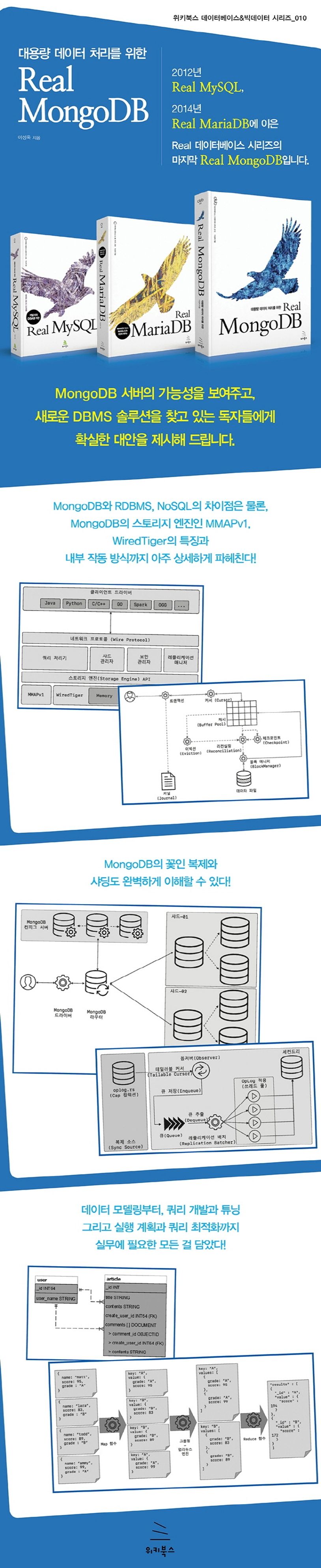
MongoDB 메뉴얼은 아주 간결하고 기본적인 내용에 충실하게 작성되어 있다. 하지만 문법이나 명령만으로는 DBMS를 사용할 수 없다. 내부 작동 방식을 모르면 수많은 시행착오를 거치게 되며, 이런 시행착오는 결국 서비스 품질 저하로 연결될 것이다. 이 책에서는 MongoDB 서버를 사용하는 데 꼭 필요한 아키텍처와 함께 MongoDB 내부(Internal)에 대해 자세히 설명하고 있다. 또한 다양한 시행 착오를 줄이기 위한 주의 사항들에 대해서도 설명한다.
이 책은 MongoDB 서버(특히 MongoDB 1.x와 2.x 버전)에 실망했던 독자들에게 다시 한 번 MongoDB 서버의 가능성을 보여주고, 새로운 DBMS 솔루션을 찾고 있는 독자들에게 대안을 제시해 줄 것이라 생각한다.
이 책은 MongoDB 서버(특히 MongoDB 1.x와 2.x 버전)에 실망했던 독자들에게 다시 한 번 MongoDB 서버의 가능성을 보여주고, 새로운 DBMS 솔루션을 찾고 있는 독자들에게 대안을 제시해 줄 것이라 생각한다.
Real MongoDB
$51.94
- Choosing a selection results in a full page refresh.